Главная » » Основе TalusVortexFX 32/28 конструкция узла нм
21:13
Основе TalusVortexFX 32/28 конструкция узла нм
Предисловие
Ток высокого класса ASIC / ASSP / разработчикам SoC устройство может рассмотреть на три категории: основные, ранние и технологии лидеров. Момент написания этой статьи, основные разработчики работают 65-нанометровой технологии проектирования узла, рано разработчиков усыновителей ориентированы на 45/40 конструкция узла нм, и разработчик технологии лидеров стремится 32/28 нм и на последующий период Малый узел схемы. С развитием темпы внедрения новых технологий ускоряется, следующее поколение ранних к 32/28 время перехода нм узел не будет долго, и их основных разработчиков коллеги будут следовать.
Дизайн 32/28 узлов нм столкнетесь с множеством проблем, в том числе: Low-Power Design, перекрестные помехи эффекты, процесс изменения и количество режимов работы и углы значительное увеличение. Эта статья представит вам Магма Талус ® Vortex1.2 физической реализации на высоком уровне ввиду процесс, то будет ввести 32/28 конструкция узла нм и описать некоторые из вопросов, содержащихся в TalusVortex1.2 в том, как решить эти проблемы.
В дополнение к этим техническим вопросам, 32/28 узел нм, увеличение размеров и сложности дизайн проекта также создали ресурсов (без расширения размер предпосылка команду для достижения лучших результатов, при сохранении или даже снижении текущее расписание), аппаратного ресурсов (нет необходимости увеличить объем памяти или купить новое оборудование, использование существующего оборудования и серверов для обработки более масштабный проект), для удовлетворения все более сжатые сроки и другие аспекты развития вопросов, связанных с увеличением. Чтобы решить эти проблемы, в настоящем документе будут описаны инновационные через TalusVortexFX DistributedSmartSync ™ (распределенных интеллектуальных синхронизации) технологии, TalusVortex существенно увеличить свой потенциал и производительность. TalusVortexFX обеспечивает первое и единственное решение для распределенных макета.
TalusVortex1.2 физический процесс реализации описанных
1 приведены стандартные TalusVortex1.2 зрения высокого уровня физических процессов. Из рисунка, вы наблюдаете, что это не трудно предположить существование чипа списка соединений уровне списка соединений, возможно, были приняты магмы или сторонних вступления дизайн и синтез инструменты создания.
Рисунок 1. Стандартные TalusVortex1.2 процесса на высоком уровне просмотра
Первый шаг, готовый список соединений; Это включает в себя множество задач, таких как: таких, как определение ввода / вывода панели (I / Opad) и расположение всех макросов клеток. Второй этап, типовой формой ячейки (это глобальная маршрутизации в то же время, поскольку проводка может повлиять на расположение ячейки и ячейки макета также влияние на макет.)
После завершения первичного размещения ячейки, часы дерево, третий шаг является всеобъемлющим, будут добавлены в проект. Большинство осуществления часы инструмент синтеза дерево не является истинным мульти-многопользовательский режим углу (MMMC) часы осуществления дерево, но сроки среды разделены на лучшем случае (лучшем случае), а в наихудшем случае (в худшем случае) углу. Однако такой подход является слишком пессимистичным, это приведет к производительности был в "никаких улучшений" статус. В 32/28 узлов нм, MMMC реального дерева часы необходимо (см. также ниже 32/28 нм тему "вопросы MMMC" раздел). Таким образом, часы Talus1.2 синтеза дерева развернуть полный анализ MMMC, среднее время ожидания на 10% и 10% от общей площади для улучшения реализации более сложных уменьшить надежность часы системы, как показано на рисунке 2
Рисунок 2. Все дерево MMMC часы синтеза для достижения более продвинутых надежность системных часов
Как только часы дерево успешно добавлен, то четвертый шаг для выполнения комплексной оптимизации. Следующим шагом является пятым подробную проводки. Talus1.2 процесс конвергенции, чтобы конец подробную маршрутизации и сроки можно увидеть в начале процесса тесно связаны сроки, даже если принять во внимание помехи верно (см. также ниже 32/28 нм тему "помехи" раздел).
32/28 нм низким энергопотреблением
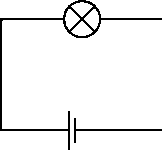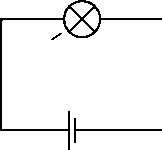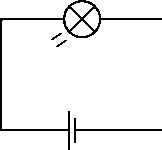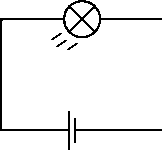
Рисунок 3. Питание наибольший интерес для микросхем
Инженеры могут использовать различные методы для управления динамическими (переключение) устройства власти и токов утечки. К ним относятся (но не ограничиваются ими) Multi-порог переключения (мульти-VT) транзисторы потребляют больше энергии, мульти-напряжение (MSMV), динамическое напряжение и частота масштабирования (DVFS) и выключения (PSO).
Во многих случаях, порог переключения транзисторов, некритических путей сроки от токов утечки ниже единицы, более низкий расход энергии, скорость переключения медленнее высокий порог переключения (высокая-VT) транзисторы форме; критический путь сроки Устройство может быть выше на величину утечки, потребляемая мощность более значительно ускорить скорость переключения, низкий порог переключения (низкая-VT) транзисторы форме.
Multi-Power нескольких напряжения (MSMV) чипы включены можно разделить на различные регионы (иногда называемый "напряжение островов" или "напряжение область), различные регионы имеют различные напряжения питания. Отнесены к более высокой напряжение будет иметь блок острова высокую производительность и энергопотребление, а также назначены низкое напряжение острова блоков будет иметь меньшую производительность и низкое энергопотребление.
Динамическое напряжение и частота масштабирования (DVFS) через использование технологий для изменения одного или нескольких функциональных блоков связанные напряжения или частоты для оптимизации производительности и энергопотребления компромиссы между ними. Например: 1,0 Номинальное напряжение низкой активности в функциональный блок может быть сведена к 0.8V для снижения потребления энергии, или в случае необходимости он также может быть увеличена до 1,2 В для повышения производительности. Аналогичным образом, номинальная тактовая частота блоков относительно низкий уровень активности сводится к половине времени, или он может быть также повышена для удовлетворения краткосрочных вспышки двойной потребности высокой производительности.
Как следует из названия, выключения питания (PSO) означает отрезать выбранного в настоящее время не используются в силовой блок. Хотя технологии для экономии энергии в эффект очень хороший, но это действительно необходимо рассмотреть многие вопросы, такие как: Чтобы избежать бросков тока, по специальному заказу в соответствующих функциональных блоков от питания и электроэнергию.
TalusVortex1.2 обеспечивает полную интегрированную решения с низким энергопотреблением, в том числе автоматизированных маломощных комплексного подхода, с несколькими напряжения и частоты межрегионального анализа и оптимизации параллельной комбинации. Talus1.2 используется не только различное число транзисторов порог переключения предела, а также поддерживает неограниченное напряжения, частоты и мощности отрезать области. Кроме того, Talus1.2 полностью поддерживает общего электроэнергетического Формат (СПЛ) и единой электроэнергетической Format (ГПП). Эти два формата позволяют конструкторских коллективов, чтобы начать с власти понять точки зрения дизайна намерениях, а затем вниз по течению диск планирования, осуществления и контроля стратегии (см. врезку).
32/28 перекрестных помех нм
Продолжает улучшаться тактовой частоты и уменьшение напряжения питания означает расширение типа перекрестных помех изменения задержки, например, отказ функция целостности сигнала (SI) эффект в повышении чувствительности. В 32/28 узлов нм, рядом с последних трека, поперечного сечения (32/28 нм узла, высота орбиты может быть больше ее ширины, как показано на рисунке 4, что увеличивает емкость связи между соседними композиций) и металла треков и отверстий для повышения сопротивления (условно говоря), эти эффекты еще более возрастает.
Рис 4.32/28 нанометровой узел может превышать высоту ширины колеи.
Talus1.2 комплекса орбитального основе алгоритма оптимизации Известно, что позволяет пользователю ранее в процессе глобальной маршрутизации перекрестных помех проблема может быть решена в течение периода. Talus1.2 решить проблемы помех Есть много способов, самый основной способ заключается в использовании лучших назначение слоя и маршрутизации через распространение имеющихся ресурсов; ему удастся избежать этой длины диффузии или число дырок вызвано значительным отрицательным воздействия. Кроме того, глобальный маршрутизатор поставляется с числом функции потока, высокий уровень производительности имеющихся.
Для того чтобы получить высокую производительность, все глобальные маршрутизатор будет открыта гипотезы. Такие как: "ведро (ведро)" в размещении провода, каждый "ковш" в свинца установлены в верхней части друг с другом, так что можно визуально увидеть начало. В большинстве сред, реальный поток вниз по течению от заказа и оформление путевых работ остается подробную маршрутизатор для завершения. Решение потока вниз по течению больше тратить на перекрестных помех вопрос по порядку величины энергии и требует ремонта (такие, как: увеличение размера единицу площади и будет сопровождаться соответствующим увеличением мощности утечки) не может быть лучше, и даже метод, который будет завершен.
В самом деле, только в том, что их пространственные отношения между орбитального упорядочения можно точно оценить потенциальные последствия перекрестных помех. Поэтому Talus1.2 трек сегментов в глобальном пространстве, расположение раздела можно использовать этот раздел еще на ранних этапах процесса оценки потенциальных помех; этой глобальной маршрутизации стадии переназначения линии и настройки, все проблемы перекрестных помех могут быть решены более ранней стадии процесса. В глобальной маршрутизации фазы изменения, внесенные в следующем ниже по течению процесса также может быть использован для руководства подробную маршрутизатора, так что мы можем быть гораздо меньше вычислительной работы лучшее решение.
32/28 проблемы процесса нм изменения
За 180 нм узла техники и высшего производства кремниевых чипов, нужно решить некоторые небольшое количество различий между пластины, пластины отличается от зерна в сроки (производительность), характеристики энергопотребления различных . Это различие может быть связано с одного на другой литейного литейного изменение процесса и оборудования, операционной среде в результате незначительные различия, такие как: температура, уровень легирования концентрация офорт, литография маску форме пластины и так далее.
При более высоких узлов технологии, все процессы изменчивости между зернами (каждое зерно на том же разница пластины), и зерно изменения в процесс (то же различия между регионами на зерно) относительно не так уж важно. (Размер зерна изменения также известен как "глобальное", "чип на чипе", "зерна на комбайн" вариант.) Например: если напряжение питания ядра чипа от 2,5 В, предполагается, в большинстве случаев зерна последовательное и стабильное напряжение 2,5 В; же предположениях бы равномерно на весь температуры чипа зерна.
С размером новых узлов технологии становятся все меньше и меньше поверхности между зерен и изменения в процессе приобретает все большее значение. Некоторые из этих изменений является изменение системы, которая означает, что он будет функционировать как изменения схемы на уровне ячейки. Например: недалеко от центра производства чипа пластине и к краю пластины чипа производятся по сравнению с некоторыми из своих связанные параметры могут быть различными, в этом случае, мы можем предсказать все параметры будут аналогичны воздействия, и случайные изменения некоторых параметров будет в случае независимых колебаний, говорит, это может быть основано на региональные различия (в отличие от расстояния основе вариации).
Рисунок 5. В 32/28 узел нм, различия между зерен и это очень важно.
Между зерен и изменения в процесс называется на-чипе вариации (ПХВ), в 32/28 нм узел становится чрезвычайно важным. Это потому, что с введением каждого нового узла технологии, структуры управления, такие как ширина транзисторов и толщины, критические орбиты и размер оксидного слоя становится все труднее, в конечном итоге приводит к относительному изменению процент (по сравнению с некоторыми из значений) будет С каждым новым узлом технология становится больше.
OCV решением является использование традиционного метода первого порядка схеме (первый orderapproach), в том числе применение чипа пакет терпимости. Однако, в 32/28 узел нм, такой подход является слишком пессимистичный и приведет к более-дизайн, проектирование и выполнение цикла сроки закрытия, сокращения дольше. Таким образом, развертывание комплекса высокой Talus1.2 ПХВ (AOCV) алгоритм, основанный на близости к ячейке и отслеживать (например: две смежные клетки с противоположных концах зерна в две единицы по сравнению с потенциальной неустойчивости связаны друг с другом более меньше), чтобы применить контексте конкретных снижением стоимости. Это более реалистичная модель может уменьшить избыточный запас, тем самым снижая пессимизм сроки нарушений, а также улучшенную производительность устройства.
32/28 нм многомодовый нескольких углу (MMMC) проблема
В дополнение к тем, упомянутых в предыдущем изменения производственного процесса, мы также должны учитывать микросхем, используемых в условиях окружающей среды (таких как: напряжения и температуры) есть вопрос о потенциальной неустойчивости. Все эти изменения могут быть отнесены к PVT (процесс, напряжения и температуры) охват проекта.
Для более ранних узла технологии устройства создается между зернами и между зернами незначительно PVT. У первой гипотезы, основанные на поверхности чипа и то же вариации процесса с тем, что, исходя из цельного зерна имеют стабильное напряжение ядра и температуры и других условий окружающей среды, чтобы упростить работу тем, что это возможно. Исходя из этих предположений, с помощью серии BeSe-случае условия (максимально допустимое напряжение, минимальная допустимая температура и т.д.), чтобы определить каждый путь BeSe-случае (как минимум) задержка будет сравнительно легко; Кроме того, с помощью серии наихудших условиях (минимально допустимое напряжение, максимально допустимая температура и т.д.), каждый путь для определения наихудшего (максимум) задержка будет сравнительно легко.
Рисунок 6. В 32/28 узлов нм необходимость решения большого числа мод и углы.
Если наихудший и наиболее casePVT конкретных ряд условий, таких как то, что мы называли "углу". В 32/28 узел нм технологии, между зерен и очень очевидные различия в PVT для решения большого числа мод и углы работы является существенным. Кроме того, ранее упомянутых методов маломощных дизайн сделает проблему более сложной. Например: в нескольких поставку нескольких напряжения (MSMV) технологии случае, напряжение может быть напряжение острова минимально допустимого диапазона напряжения напряжение, напряжение на другое напряжение острова находится в пределах допустимого диапазона напряжений из самых высоких напряжений, а остальные острова напряжения Напряжение между ними. Другой пример: некоторые чипы имеют различные режимы работы, с одним или несколькими модулями цепи расположены в центре прекращения подачи энергии приведет к необходимости анализа размером зерна углу случаев значительно возросло.
Проблема в том, что существующих инструментов: период осуществления, чип должны быть оптимизированы в перспективе MMMC. Многие существующие системы предполагалось сначала рассматривает наихудший сценарий, а затем оптимизировать условия другим способом приступить к задаче оптимизации. К сожалению, это может привести к чрезмерному пессимизму, в результате чего субоптимального производительности. Еще хуже то, что, если на худшем случае это предположение неверно, то результат может быть получен полностью, независимо от используется чип. Talus1.2 построен MMMC собственные возможности обработки, что означает, что процесс оптимизации не пропустите ни одной сцены. Кроме того, Talus1.2 высокая скорость и большая емкость также означает, что он может принимать во внимание не только небольшое подмножество реализации сценариев, но этот инструмент должен иметь дело с целой семьи подписать ядерного сценария. Таким образом, Talus1.2 обеспечивает лучшую производительность и более коротких циклов выполнения.
Для DistributedSmartSync технологии для повышения производительности TalusVortex
Упоминалось ранее физической реализации каждого этапа процесса принадлежат вычислительно сложных задач. И с технологий для решения повышенной сложности узлов, каждый узел должен выполнять расчет также улучшается. Кроме того, при интегрированной функции устройства возрастает, конструкция размера и сложности будет расти с каждым узлом и физической реализации соответствующих вычислительных задач соответственно увеличится.
Еще один фактор: размер модули (модуль функции, необходимые для достижения числа клеток) с каждой функции будет все больше и больше функций, упакованных в постоянно растет. Некоторые команды предпочитают иерархическую физических решений осуществления, в то время как некоторые команды предпочитают использовать "плоские" программы, потому что они чувствуют при использовании иерархической схеме, чтобы дать слишком много.
Если инструмент имеет мощность переработки больших цепи модуль, то производительность труда может быть сразу же улучшилось. Например: определить и точную настройку уровня ограничений между модулями является чрезвычайно ресурсоемкой и трудоемкой работы. Если эти инструменты для обработки больших модуля емкость цепи, то определение суб-модулей без ограничений, потому что она не будет иметь никаких вспомогательных модулей существует. Это позволит значительно повысить производительность.
Проблема: Большинство решений ограничены макет может обрабатывать только несколько миллионов единиц. Это часто заставляет инженеров для достижения физического ограничения инструмент пришлось вручную раздел цепи модулей. Это также оказывает влияние на производительность инженеров.
Расширение каким-то образом, кроме как через, в противном случае даже самые передовые размещения и маршрутизации решение Talus1.2 фактическая емкость имеет только 2 млн. до 5 млн. единиц между производством ставка, предлагаемая на 100-150 млн. единиц в день . Результаты создаст потенциал обусловлен разрыва в производительности. Чтобы справиться с 32/28 нм узла разработке, осуществлении, в том числе более 10 млн. единиц плоского модуля схема имеет важное значение, как показано на рисунке 7 (см. врезку).
Рисунок 7. Физическая реализация инструментов ненасытный спрос на плоские емкости.
В прошлом, был многопоточности возможностей путем предоставления физическим инструментов реализации для повышения емкости и производительности. В некоторых случаях эти функции "механически" для традиционных инструментов, эффект ограничен. В отличие, Talus1.2 все инструменты полностью интегрирован с встроенным в многопоточных возможностей.
Цянь Вэньи говорит, что роль несколько потоков на инструмент является весьма ограниченным; основаны на законе Амдаля (Amdahl'slaw) и других законов информатики, (наряду со своим основным работает в каждом потоке) нить играет все большее число Эффект становится все меньше и меньше. Проще говоря, это сказать нам, что ускорение любой программы будут распространяться ограничения на число параллельно (например, процедуры, связанные с длинной последовательности фрагментов других частях программы), как показано на рисунке 8.
Рисунок 8. Законом Амдаля отражает ограничения многопоточности.
Чтобы быть использованы для создания ASIC / ASSP / SoC устройств для физических инструментов реализации, некоторые из этих инструментов параллельно с 50% до 75%. Как мы видим на рисунке 8, "сладкое пятно (sweetspot)", в лучшем случае, использование 8-10 процессорных ядер, только примерно в 3 раза скорость доступна.
К счастью, физической реализации задач распределенного на несколько машин с Законом Амдаля может быть определена для преодоления ограничений. Показано на рисунке 9, новых DistributedSmartSync (распределенных интеллектуальных синхронизации) технологии TalusVortexFX обеспечивает физической реализации процесса через все шаги (за исключением часов синтеза дерево, этот метод не имеет функции) сочетает в себе интеллектуальную технологию синхронизации Уникальная распределенная управления. Магма будет это новое решение, называется TalusVortexFX, он DistributedSmartSync технологии расширенной Talus1.2.
Технология повышенной высокого уровня зрения процесса TalusVortexFX
Концепция данной технологии: конструкция для большего разделения или интеллектуальных модулей, будет распространен на всю сеть дизайн разделов, работающих на дизайн сервера и реализации, на заключительном этапе в основной процесс автоматически повторную синхронизацию реализации этих проектов. По существу, это позволяет дизайнеру обрабатывать большие проекты, в то же время получить больше их гораздо меньше по размеру, до схемы модуля достигнут той же пропускной способности (количество единиц в день). Даже в использовании равное число ядра / темы, когда скорость обработки распределенных программ более плоским, лучшие многопоточный процесс в 2-3 раза быстрее.
Рисунок 10. Только многопоточных против многопоточность + распределенной обработки
Физическая реализация производительности инженеры, как правило, основаны на количество единиц измерения каждый день. Использование лучших обычных процессов, может быть предоставлена максимальная производительность в целом около 1 млн. единиц в сутки. В отличие, TalusVortexFX распределенной обработки технологий для повышения фигура 200-500 млн. единиц в день, эта технология на протяжении всего процесса (только для ворот разметка, наличие более высокой производительности обновления, некоторые пользователи обеспокоены это еще один показатель).
Также проблемой является: TalusVortexFX для физических команды внедрения в начале цикла разработки для выполнения быстрого анализа способности предположений, для достижения наилучшего области компромисса между скоростью и силой. Но там не будет проигнорирован: DistributedSmartSync технология полностью укрепления существующих Talus1.2 технологии, что способствует быстрому принятию этого продукта.
Что касается сохранения существующих инвестиций в аппаратные ресурсы, DistributedSmartSync технология позволяет пользователям существующих 32 ГБ и 64 ГБ памяти для данного устройства может быть в полной мере. Если вы не используете эту технологию в пользу 32/28 конструкция узла нм, то оборудование будет требовать от пользователей перейти на 128 Гб или 256 Гб памяти устройства, нажмите большую ферму серверов, то возможно, придется потратить несколько миллионов долларов.
В дополнение к сокращению цикла разработки, улучшения проектной группы возможность использовать плоские подход (без добавления дополнительных ресурсов в рамках помещения), другие, чем для улучшения производительности инженерных групп, TalusVortexFX использования за счет сокращения времени выхода на рынок (прибыль времени) также рассматриваются как для удовлетворения растущей напряженности разработка графика проблемы.
Резюме
Для 32/28 нм и менее узлов технологии, дизайн размер столкнетесь с множеством проблем, в том числе маломощных дизайн, перекрестные помехи эффекты, процесс изменения и количество режимов работы и углы значительное увеличение. TalusVortex1.2 физической среды магмы осуществления полностью решить все эти проблемы.
Кроме того, 32/28 размер узла нм дизайна и сложности проекта также привело к увеличению ресурсов (не расширять размер команду для достижения лучших результатов), аппаратных ресурсов (нет необходимости в обновлении материнской платы, больше памяти или купить новое оборудование, используя существующие оборудования и обрабатывать большие дизайн фермы серверов) и как встретить график развития и другие аспекты все более напряженной вопросы, связанные с увеличением. Для решения этих вопросов, через TalusVortexFX инновационных DistributedSmartSync ™ (распределенных интеллектуальных синхронный) технологии, TalusVortex существенно увеличить свой потенциал и производительность.